
The Consensus Machine
What 140 years of automation tells us about AI and jobs


A few weeks ago, a Substack post helped tank the Dow 821 points.
Citrini Research published “The 2028 Global Intelligence Crisis” — a scenario where AI advances so fast that the global economy buckles under mass displacement. Fortune called it the week the AI scare turned real. Michael Bloch published “The 2028 Global Intelligence Boom” — same premise, same rigor, opposite conclusion. Will Manidis wrote “On the Garden”, a viral essay arguing through the history of Versailles and Lancelot Brown that the entire framing was wrong — that the economy isn’t a storm that happens to us but a garden tended by people making choices.
Three smart people looked at the same data and came to completely different conclusions. Citrini and Bloch both rely on single-variable extrapolation — displacement rate for one, cost deflation for the other — the pattern that has defined technology forecasting for a century. Manidis comes closest to the structural question, arguing that agency matters, that we aren’t passive recipients of technological change. But the structural question is more specific than “we have choices.” It’s about which choices, and whether organizations make them fast enough.
That question has a surprisingly clear answer in the historical record.
The Consensus Pyramid
When I say “consensus,” I don’t mean agreement. I mean the kind of work that follows established patterns — work that can be learned from existing examples and produces predictable outputs.
Summarizing a research report. Screening resumes. Matching travel itineraries to preferences. Executing a stock trade at market price. Writing a first draft of a legal brief. Generating a competitive analysis from public data.
This is the work that large language models are most reliable at producing — and that’s not incidental. It’s the fundamental mechanism. LLMs are pattern-completion engines trained on the largest corpus of human output ever assembled. The patterns that dominate that corpus are, overwhelmingly, consensus patterns. The more a task looks like something that’s been done before, the better the model performs. Every LLM is, at its core, a consensus machine.
Non-consensus work is different — the judgment call in ambiguous situations, the taste that distinguishes a good product from a forgettable one, the decision to pursue a deal everyone else passed on. And it’s something harder to name: the ability to look at discrete pieces of information and synthesize them into something none of the pieces contain on their own. Seeing the forest, not just the trees. Defining the problem, not just solving it.
Now, think of all knowledge work as a pyramid — but not as a pyramid of people. A pyramid of work.
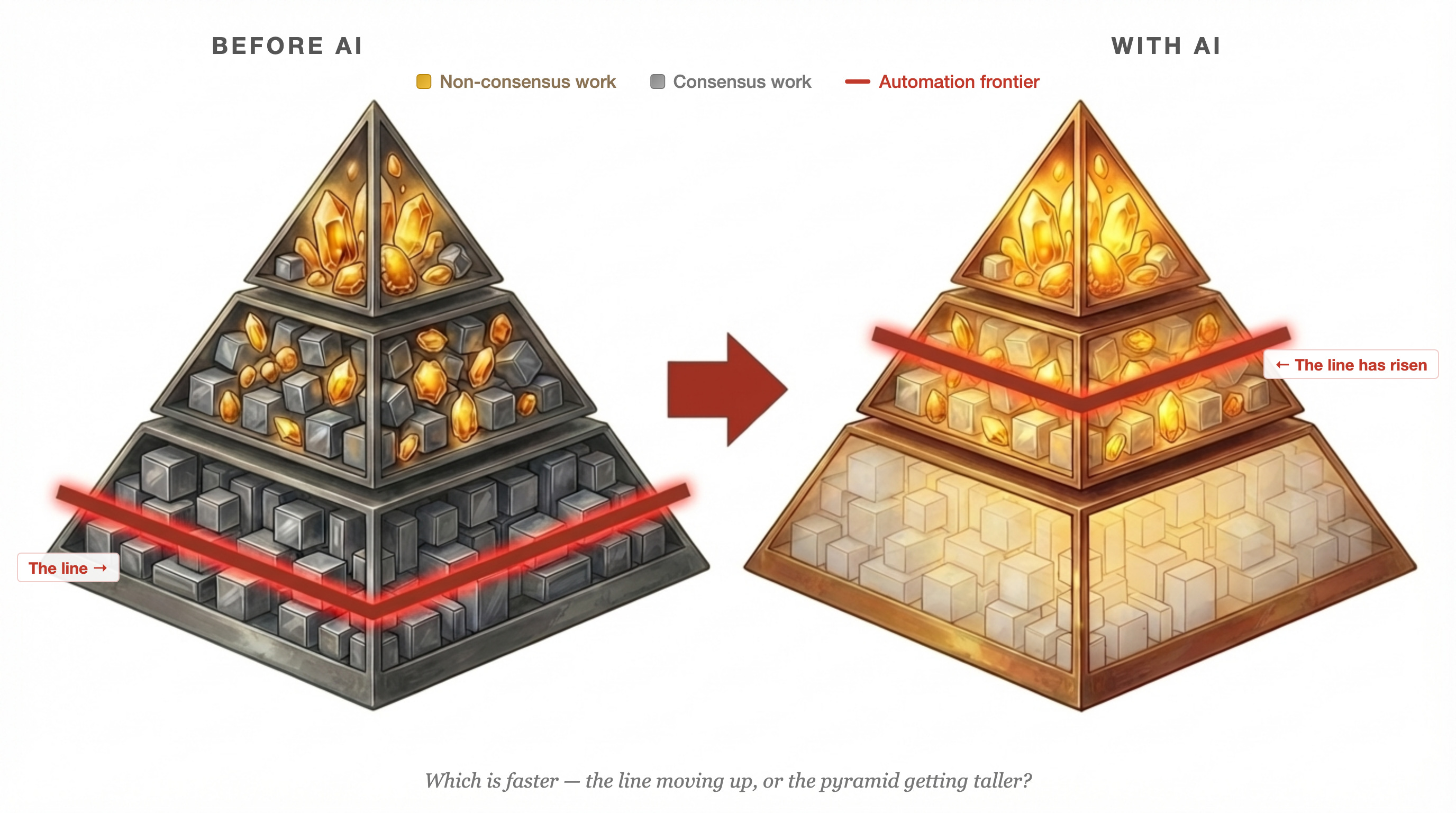
Every person’s job is a collection of work units. Some are consensus: answering routine emails, pulling standard reports, following established processes. Some are non-consensus: making judgment calls, connecting disparate information, deciding what to prioritize. Nobody’s work is 100% one or the other.
At the bottom of the pyramid, people’s days are composed mostly of consensus units — tightly packed, pattern-following, proceduralizable. In the middle, the mix is more even, and this is where it gets most interesting: coordination, project management, translating strategy into execution. At the top, the work is mostly non-consensus — strategy, synthesis, the connective tissue that ties discrete units of information into coherent direction.
There’s a line between the consensus and non-consensus layers, and that line has always existed. What’s new is that AI is automating the consensus units — not replacing whole people, but changing the composition of everyone’s work. The consensus units get handled by machines. What’s left is the non-consensus remainder.
And that composition isn’t fixed. What counts as “non-consensus” shifts as consensus gets automated. Writing a well-structured email used to require judgment. Now it’s a prompt. The frontier moves.
The question comes down to this:
Which is faster — consensus units being automated, or humans’ ability to absorb more non-consensus work?
If automation outpaces absorption, you get Citrini’s crisis. If absorption outpaces automation, you get Bloch’s boom. The historical evidence is surprisingly clear on this. And it’s more nuanced than either camp wants to admit.
The Pattern: Three Waves
We’ve seen this before. At least three times.
Electrification (1880s-1920s)
In 1899, electricity powered less than 5% of American manufacturing. By 1929, it powered roughly 75%. The consensus work it replaced was the centralized power system — belt-and-shaft factories organized around a single steam engine, where every machine’s position was dictated by proximity to the power source.
But here’s what Paul David documented in his landmark 1990 paper “The Dynamo and the Computer”: there was a 40-year lag between electrification and measurable productivity gains. The technology wasn’t slow — factory owners were. They initially just bolted electric motors onto steam-era layouts. They automated the consensus operation without redesigning the system.
The productivity surge came only in the 1920s, when a new generation of manufacturers built factories from scratch around “unit drive” — individual motors for each machine, with layouts designed for workflow, not power proximity. The non-consensus work wasn’t operating the new technology. It was reimagining the entire system around it.
The economy didn’t just absorb the disruption — it generated entirely new industries in consumer appliances, electrical engineering, industrial research, and factory design that hadn’t existed before.
Computing (1960s-1990s)
The computing wave is even more instructive, because it automated cognitive consensus work — the same category AI targets.
In the 1950s and 60s, congressional hearings and presidential commissions warned of mass unemployment from automation. In 1964, a group of prominent intellectuals — including Linus Pauling and Gunnar Myrdal — sent a memorandum to President Johnson arguing that “cybernation” would create “a system of almost unlimited productive capacity” while making most human labor unnecessary. Here’s what actually happened: clerical employment grew from roughly 2 million in 1910 to nearly 19 million by 1980, driven by expanding corporate complexity. When computers arrived, they initially intensified this expansion before eventually automating it. The inflection point — when clerical jobs peaked and started declining — didn’t come until 1980.
Since 1980, PCs and the internet have destroyed approximately 3.5 million jobs and created more than 19 million, according to McKinsey. That’s more than a 5:1 creation-to-destruction ratio. The non-consensus frontier that emerged — analysis, strategy, software development, knowledge work — was so vast it vindicated what Peter Drucker had already seen coming in 1959 when he coined the term “knowledge workers.”
But the transition was not painless. The workers displaced from middle-skill clerical roles largely didn’t become software engineers. Their children did. The transition was intergenerational, not individual. And the “hollowing out” of middle-skill work created wage polarization that persists today.
Robert Solow captured the delay in 1987: “You can see the computer age everywhere but in the productivity statistics.” It took another decade for the productivity boom to materialize.
The Internet (1990s-2010s)
The internet’s clearest case study is the stockbroker. Before online trading, executing a stock trade was consensus work: take the order, place it on the exchange, confirm the fill. The cost of a single transaction dropped 90% between 1975 and 2000.
But stockbrokers didn’t disappear. The role split. The consensus part (trade execution) was automated. The non-consensus part (financial advisory, portfolio strategy, client relationships) was elevated. Brokers who could only execute trades were displaced. Brokers who could provide judgment became more valuable.
Travel agents are the displacement case everyone cites — employment fell by more than half from its 2000 peak. But even there, the survivors moved to complex, high-judgment travel: luxury, corporate, multi-destination itineraries that require exactly the kind of taste and problem-solving AI still struggles with.
The internet went from niche to ubiquitous in roughly 10-15 years — much faster than electrification’s 40-year slog. The “painful gap” between displacement and frontier creation was shorter. But it was still painful.
The Accelerating Pattern
Here’s what the three waves tell us when you stack them up:
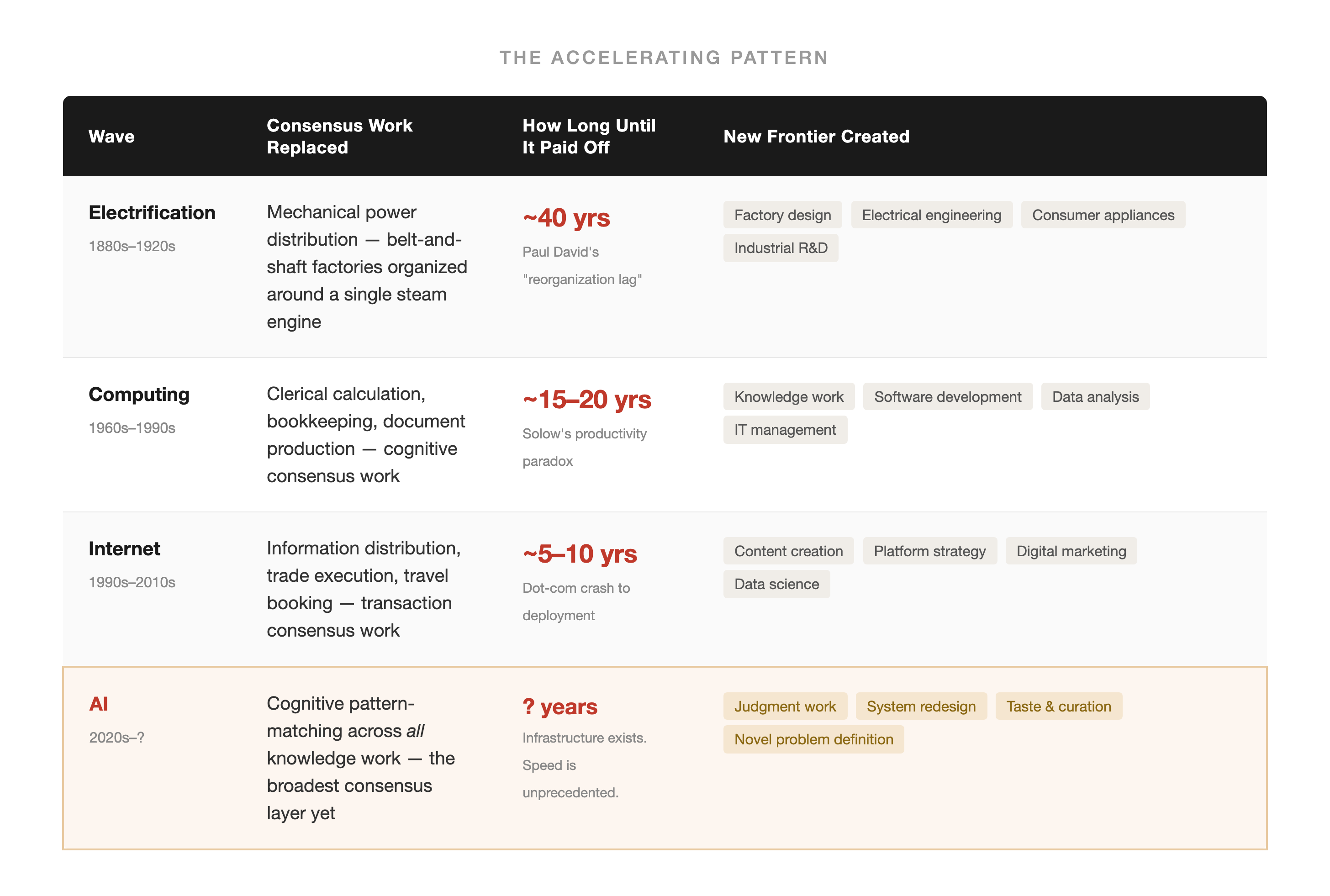
Three patterns hold across all three:
1. The technology initially creates MORE consensus work before automating it. Electrification needed more factory workers before it needed fewer. Computers swelled clerical employment for decades before the 1980 peak and decline. The internet created web content managers before it created platforms that eliminated them.
2. The painful gap between displacement and frontier creation shortens with each wave. From 40 years to 15-20 to 5-10. The question is whether AI’s gap will be shorter still.
3. Frontier expansion has always outpaced displacement — eventually. The 5:1 job creation ratio for computing is striking. But “eventually” matters. In any given 5-year window, the ratio could be inverted. And the new jobs weren’t always better than the old ones.
David Autor, the MIT economist whose framework for task-based labor economics undergirds much of this analysis, puts it this way: computers automated routine tasks (a closely related concept to what I’m calling consensus) and complemented non-routine tasks (non-consensus). The economy created new non-routine work faster than it automated routine work. The pyramid grew taller faster than the line moved up.
So Why Might AI Be Different?
Autor updated his framework in 2024 with a finding that challenges the limits of his own model. Previous technologies — electricity, computers, the internet — couldn’t automate non-routine cognitive work. They could automate calculations but couldn’t exercise judgment. There was a hard barrier that economists call Polanyi’s Paradox: we know more than we can tell, and if we can’t specify the rules, we can’t automate the task.
AI crosses that barrier. “If a traditional computer program is akin to a classical performer playing only the notes on the sheet music,” Autor writes, “AI is more like a jazz musician — riffing on existing melodies, taking improvisational solos and humming new tunes.”
This means AI doesn’t just automate the bottom of the pyramid. It can draft strategy memos and generate research hypotheses that are usable — not expert-level, but credible enough that the gap between AI output and human judgment is narrower than it was even a year ago.
The clean line between consensus and non-consensus starts moving in both directions — AI pushes it up from below while simultaneously reaching across it from the consensus side.
But — and this is where Citrini’s crisis scenario breaks down — the line has always been moving. What was non-consensus work yesterday becomes consensus work today. Writing a grammatically correct email used to require judgment. Operating a spreadsheet used to be specialized knowledge. Building a website used to be engineering.
The question was never “will the line move?” It was always “will the pyramid grow taller fast enough to absorb the people the line pushes out?”
The historical answer, across three waves and 140 years: yes, but not immediately, and not painlessly.
What the Consensus Machine Misses
The Citrini crisis and the Bloch boom share the same error: they treat the future as a single-variable extrapolation from the consensus layer.
Citrini’s model: AI disrupts white-collar work → consumer spending collapses → a deflationary spiral takes hold. The mechanism is more sophisticated than simple displacement math, but the underlying assumption is the same: if AI can do the work, the workers lose. It misses that every person is a mix of consensus and non-consensus work. Automating the consensus units doesn’t necessarily eliminate the person — it changes what they spend their time on.
Bloch’s model: AI deflates the cost of services → purchasing power rises → prosperity spreads. This is a straight-line extrapolation of productivity gains. It ignores the distributional question — prosperity for whom, and when? — and the painful gap between displacement and absorption.
Both treat the future as a math problem with one variable. The actual answer has two:
Speed 1: How fast does AI automate consensus work? Fast, though not frictionless. The distribution infrastructure already exists — internet, cloud, connected devices — which previous waves had to build or significantly expand. Natural language interfaces lower the adoption barrier. But two real constraints loom: energy capacity is already straining under data center expansion, and there’s genuine debate about how much further transformer-based models can improve as the most accessible training data gets exhausted. Even so, the deployment speed is unprecedented relative to any prior wave.
Speed 2: How fast does the non-consensus frontier expand? Historically, it always has — but unpredictably. Competitive dynamics force differentiation. New markets create new categories of judgment. The composition of new work matters as much as the count.
The gap between these two speeds is where the story plays out. And that gap is not a technology question. It’s an organizational question.
The Reorganization Bottleneck
Paul David’s electrification insight is the most important finding in this entire research: the 40-year productivity lag wasn’t a technology lag. It was a reorganization lag. Factories had the electric motors. They didn’t have the organizational imagination to redesign around them.
The pattern repeats today. Many large firms remain in incremental mode — automating legacy tasks instead of using AI to reimagine workflows entirely.
It’s the same mistake and the same lag, a hundred years apart. Anthropic’s own research, published last week, quantifies the contemporary version: even in occupations where AI could theoretically handle the majority of tasks, actual deployment remains a fraction of what’s technically feasible.
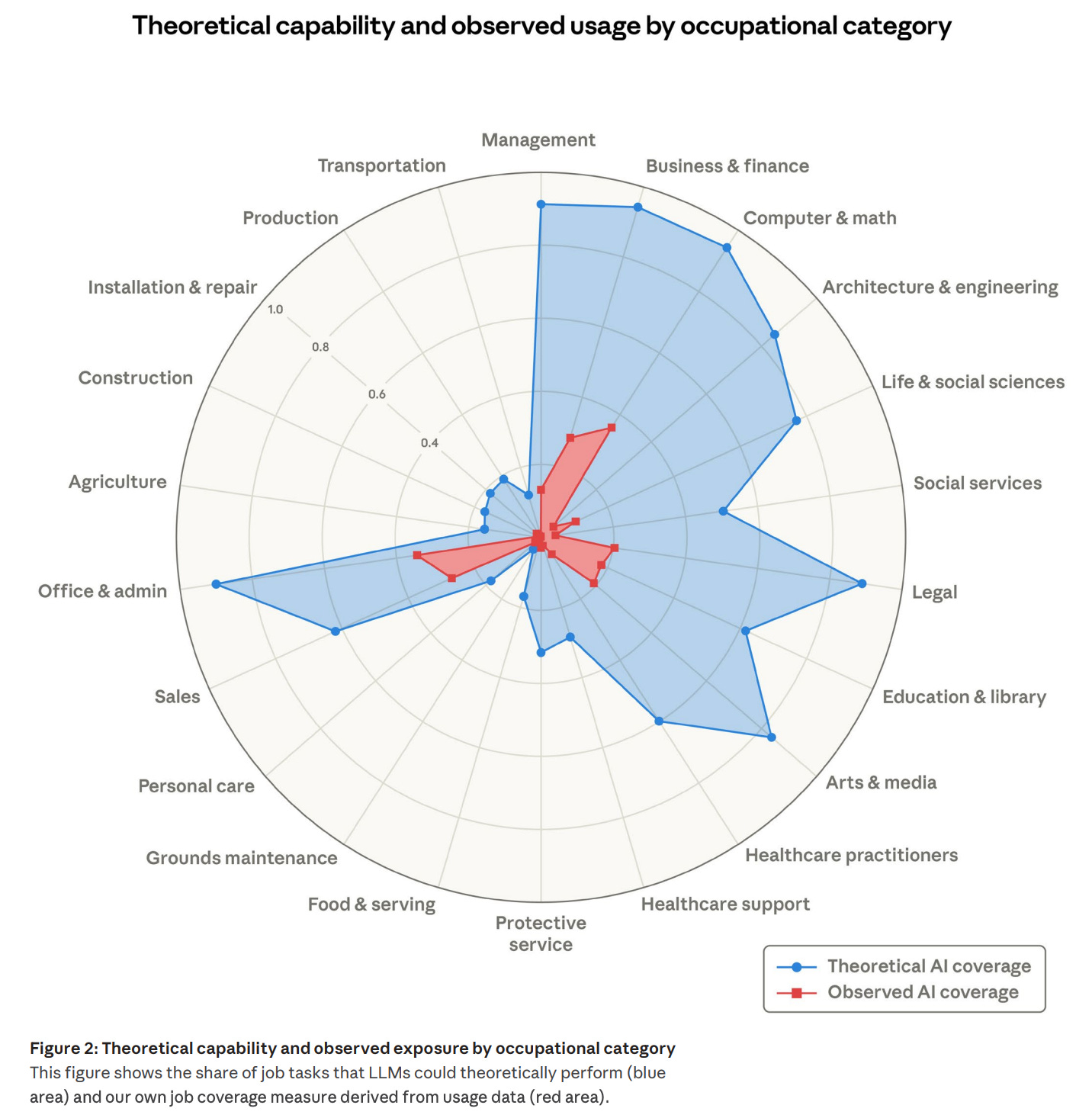
In Computer & Math occupations, theoretical AI capability reaches 94% — but actual deployment sits around 33%. The gap is the reorganization bottleneck.
The technology isn’t the bottleneck. The reorganization is — just as it was for electric motors. Redesign is inherently non-consensus work — it requires judgment about what the new system should look like, taste about what matters, and courage to abandon what’s working well enough.
This is what I see in my own work. At NextView, we built an agent to systematically surface and evaluate prospects outside our existing network — companies that traditional relationship-driven sourcing would miss.
What the agent handles is the consensus work of scanning: ingesting large datasets, scoring against criteria, surfacing companies worth a closer look. But here’s the design choice that matters — we intentionally calibrate for a wide net. We’d rather have false positives (borderline companies that come through for a partner to evaluate) than false negatives (non-obvious prospects that get filtered out because they don’t fit the pattern). The agent does the consensus-level labor of scanning. The non-consensus judgment — including deciding that something looks weird enough to be interesting — stays with the partners.
At a firm like ours, where we don’t have junior investment team members, the trade-off without the agent was clear: either we don’t look at prospects outside our network at all, we hire a junior team, or partners spend time on scanning that would be better spent on the work only they can do — evaluating founder judgment, stress-testing market assumptions, connecting patterns across the portfolio that no individual deal memo contains.
The three hours a partner saves aren’t gone — they’re redirected to the most irreplaceable work in the firm.
But not every version of this story plays out the same way. The same dynamic looks different depending on where you sit in the pyramid — and that’s where it gets more complicated than any single prediction captures.
Three Stories in the Pyramid
“Will AI take my job?” assumes one answer that applies to everyone. The work-composition lens reveals at least three different stories playing out simultaneously.
The bottom: displacement and liberation
For people whose days are composed almost entirely of consensus units — data entry, routine processing, standard report generation — AI automation is genuinely a displacement story. Not because these people lack value, but because the work they were hired to do is exactly what the machines are built to produce. The historical parallel is precise: not every factory worker displaced from the belt-and-shaft line became a factory designer. Many didn’t. The computing wave’s transition from clerical work to knowledge work was intergenerational — the displaced workers’ children became software engineers, not the workers themselves.
But there’s a second story at the bottom that the crisis narrative misses entirely. Some people are stuck in consensus work not because it’s their ceiling, but because it consumes all their bandwidth. The analyst buried in data cleaning who never gets to do analysis. The associate generating pitch books who never gets to evaluate deals. The nurse spending hours on charting who never gets to focus on patient judgment.
When AI lifts the consensus burden, these people don’t get displaced — they get liberated. They finally have time for the non-consensus work they were always capable of but never had the bandwidth to do. This is what Autor means when he writes that AI could “extend the relevance, reach, and value of human expertise to a larger set of workers” — not by making everyone an expert, but by removing the consensus floor that kept capable people from reaching their ceiling.
The dividing line is whether someone has synthesis capacity that was buried under consensus work, or whether the consensus work was all they had. That’s a hard question, and the honest answer is that for many people at the bottom, it’s genuinely a displacement story.
The middle: the translation problem
The middle of the pyramid is the most interesting and the least discussed. These are people with a genuine mix of consensus and non-consensus units in their day — project managers, team leads, department heads, middle management broadly. Their non-consensus skill was often coordination: synthesizing input from multiple people, translating strategy into execution, making judgment calls about priorities and resource allocation.
When AI automates the consensus units below them, the coordination challenge transforms. Managing a team of people doing consensus work is a different skill from directing AI systems that do the same work — the judgment is similar (what should we prioritize? what does quality look like?) but the execution layer is entirely new.
This is a translation problem, not an elimination problem. The people in the middle who can redirect their coordination instincts — who can manage AI workflows with the same judgment they used to manage human teams — become dramatically more productive. The ones who can’t make that translation face a version of the same displacement the bottom faces, just from a higher starting point.
The top: the rising bar
For people at the top of the pyramid, AI doesn’t threaten displacement. It raises the competitive bar.
When the consensus units below you get automated, you can go deeper. The strategic work you used to squeeze between meetings and reviews now has room to breathe. The pattern recognition you exercised across a narrow slice of information can now span a much wider field, because AI handles the gathering and summarizing that used to eat your time.
But everyone else at the top gets the same advantage. Strategy that was differentiated last year becomes table stakes this year. The synthesis that made you valuable when information was scarce becomes expected when information is abundant. The non-consensus bar keeps rising — not because the work gets harder in absolute terms, but because the baseline keeps climbing.
Why the Frontier Keeps Expanding
Competitive dynamics, not optimism, drive frontier expansion. When everyone can produce the same consensus output, that output gets commoditized. The only way to capture value is to do what the machines can’t do yet — to find the differentiated angle, the synthesis, the thing nobody else is offering.
This is what every previous wave actually looked like. Electrification commoditized centralized power, so the value shifted to factory design. Computing commoditized calculation, and an entirely new category of knowledge work emerged. The internet commoditized information distribution, so the value shifted to curation and strategy. Each time, the consensus layer got cheaper and the non-consensus frontier got more valuable — because scarcity is what drives returns, and non-consensus work is what’s scarce.
The factory owners who redesigned around unit drive in the 1920s captured the next fifty years of industrial growth. The ones who bolted electric motors onto steam-era layouts got acquired or went bankrupt. The technology wasn’t what separated them — the willingness to reorganize was.
That’s the question this moment is asking — of individuals, of companies, of entire industries. The consensus units are being automated. The question is whether you’re reorganizing around what’s left — the judgment, the synthesis, the ability to look at ten separate data points and see the one pattern that connects them.
At the bottom, that means asking honestly whether you’re displaced or liberated. In the middle, it means figuring out whether your coordination skills translate to a new medium. At the top, it means asking whether you’re going deeper or coasting on a bar that’s about to rise.
What’s one part of your work that felt like judgment five years ago — and feels like pattern-matching now?
Previously in Ground Truth: The Leash Length Problem explored how much autonomy to give AI systems — and the architecture required to extend it. The consensus machine reframes the question: the leash length problem is really the middle layer’s translation problem, applied to one firm at a time. The Structural Divide explored why enterprise AI productivity lags individual breakthroughs — the reorganization bottleneck, before I had a name for it.
Thank you!