
The Leash Length Problem
What managing people teaches us about managing AI — and where the analogy breaks

At a Lunar New Year party last weekend, I was telling another parent about the app I built for our kids — a Chinese character learning tool I made with Claude Code, Anthropic’s AI coding agent. She’d been a professional before staying home with her kids, and she asked the question I think everyone wants to ask about AI but doesn’t know how to frame:
“But how do you know it’s right? Don’t you need to check every character against a dictionary?”
I gave her the answer that I’ve realized is the most honest one I have: “The same way you’d know any work your junior people did was right. You don’t check every line. You ask them about their plan, you evaluate whether the plan makes sense, and you observe what happens in production.”
I’m not going to manually verify every dictionary pair in the database. But I’ve accepted the trade-off: this is a low-stakes production environment, I’ll catch mistakes through use, and the alternative — building everything by hand — means the app doesn’t exist at all.
That answer didn’t come naturally to me. It took six months of working with an AI agent to develop the mental model behind it. And I think the framework that emerged — thinking about AI delegation the way we think about people management — has implications well beyond my little app.
You’re reinventing management — whether you realize it or not
That answer I gave at the party — “the same way you’d manage a junior employee” — turns out to be more than an analogy. As Ethan Mollick has argued in “Management as AI Superpower”, working with AI agents is fundamentally a management problem. The same skills — clear delegation, knowing what “done” looks like, checking work at the right level of detail — are what separate effective AI users from frustrated ones.
I’d take it a step further: we’re not just reinventing management. We’re recapitulating the entire history of how organizations learned to delegate. The toolkit is remarkably parallel — up to a point.
My accidental management journey
I am not an engineer by training. I helped scale a company from 20 people to IPO as a product leader and spent eight years evaluating startups as an investor. Now I work daily with Claude Code across everything from building apps to automating investment workflows to developing product strategy. It’s become a general-purpose work partner, not just a coding tool. When I started, watching every step was the point. I’d read Claude’s reasoning, see what commands it chose and why, observe how it handled errors. Like sitting next to a senior engineer and learning by watching.
Eventually I got comfortable and turned on “accept edits” — letting Claude read and write files without asking me each time. But here’s the thing about Claude Code: it can do anything on your computer that you can do. Open any file, run any command, install any package. That power is exactly why it asks permission before every action — and anyone who’s used it knows that means dozens of approval prompts per session.
There was an option to skip all permission checks entirely. But I didn’t have the security guardrails in place, and I’m not the person who instinctively knows which commands can damage a system. So I lived in a middle ground that satisfied nobody: I couldn’t walk away for ten minutes without coming back to find Claude waiting on a permission prompt, the whole session stalled.
Then, six months in, I tried something different: I asked Claude to audit its own permissions.
The human management stack
Before I describe what happened, consider how organizations actually solved the delegation problem with humans. It wasn’t one big decision to “trust people.” It was a stack of infrastructure that built up over decades:
Observation: You watch the new hire’s work closely. Not because you don’t trust them — because you’re calibrating. Learning their strengths, their blind spots, where they need guidance.
Processes and artifacts: Checklists, SOPs, templates, style guides. These aren’t bureaucracy for its own sake. They’re externalized judgment — the organization’s way of saying “here’s how we think about this” so individuals don’t have to reinvent it.
Graduated trust: Fewer mistakes → more responsibility. The new hire who handles small projects well gets bigger ones. This is empirical, not theoretical. You’re not deciding to trust them. You’re observing that trust is warranted.
The social contract: And here’s the piece that makes everything else work. A human employee has skin in the game. Their reputation, their career, their livelihood depends on doing good work. If they make a catastrophic error, there are consequences — for them. This accountability creates a feedback loop that self-regulates — which is why people internalize the standards even when nobody’s checking. Their identity is tied to their performance.
AI agents are building the same stack
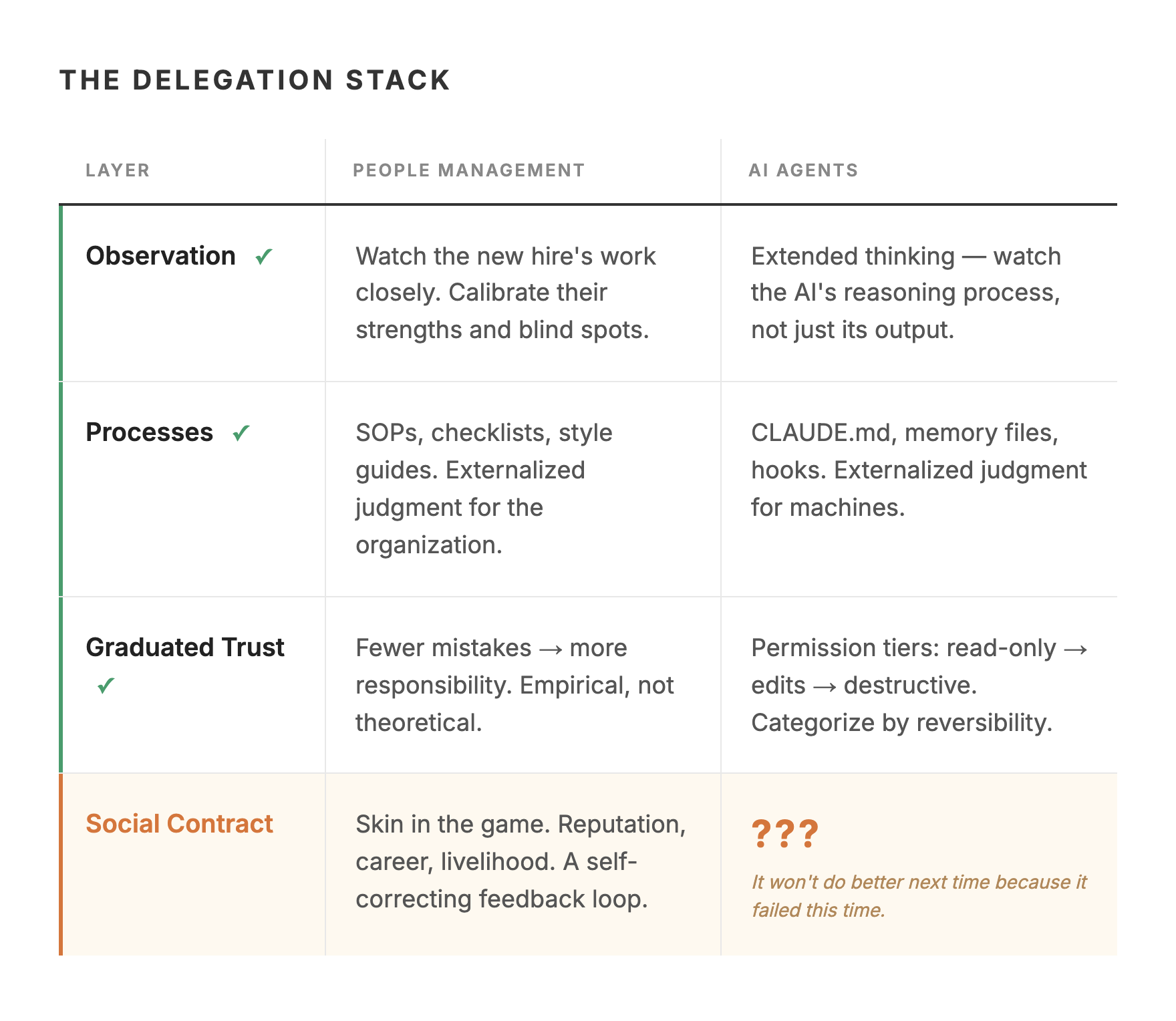
AI development tools are recapitulating this pattern with surprising precision — every layer of the management stack has a direct equivalent:
Observation → Extended thinking. Claude Code has a mode that lets you watch the AI’s reasoning process in real time — not just its output, but how it approaches problems. This is the equivalent of sitting next to your new hire and seeing how they think, not just what they produce.
Processes and artifacts → CLAUDE.md, memory files, hooks. These are literally externalized judgment for AI. A CLAUDE.md file tells Claude “here’s how we think about this project.” Memory files persist learnings across sessions. Hooks automate compliance checks. These are SOPs for machines.
Graduated trust → Permission tiers. When I asked Claude to audit its own permissions, it came back with three tiers that any manager would recognize:
Auto-approve (reversible, read-only): File reads, directory listings, running tests — the equivalent of letting your hire read company documents without asking permission.
Gate but don’t block (visible changes): File edits, new files, installing packages — like letting your hire draft documents. Review the output, not the process.
Always require approval (destructive or irreversible): Force pushes, database deletions — the decisions where a senior person should always weigh in.
This is role-based access control, but arrived at through the same logic managers use: categorize by reversibility, not by fear.
What made the difference, by the way, wasn’t learning to code — it was learning to ask. Instead of being directive — “allow this command, block that one” — I asked Claude to analyze the gap and recommend a framework. AI’s strength isn’t just executing; it’s researching and planning. By evaluating its plan rather than micromanaging its actions, I was doing exactly what good managers do: judge the thinking, not just the output.
Where the analogy breaks — and where it doesn’t matter
The first three layers of the human management stack — observation, processes, graduated trust — translate almost perfectly to AI. But the fourth layer doesn’t: the social contract.
When you delegate to a person and they fail, there are consequences — for them. Their reputation takes a hit. Their next project gets more oversight. In extreme cases, they lose their job. People internalize standards because their identity is tied to their performance. When you delegate to an AI agent and it fails, the consequences land on whoever deployed it. The AI has no reputation to protect, no career to jeopardize, no reason to be more careful next time beyond whatever you’ve configured in its instructions.
Researcher Fabrizio Dell’Acqua calls the risk of over-delegation “falling asleep at the wheel” — in a field experiment with 181 professional recruiters, those given high-quality AI actually performed worse than those given lower-quality AI. They spent less time on each case, blindly followed AI recommendations, and became “lazy, careless, and less skilled in their own judgment.” I think part of the reason is structural: the social contract that keeps human delegation honest doesn’t exist in human-AI delegation.
What I’ve come to believe is that for a large category of work, architecture can substitute for the social contract entirely — and it might actually be better.
My three-tier permission model doesn’t need Claude to “care” about its reputation. It makes destructive actions structurally impossible without approval. Git gives me version control. Hooks catch rogue configurations. The environment is safe not because the agent is accountable, but because mistakes are reversible. This is why software engineering is the natural starting point for AI agents — the infrastructure to make mistakes cheap and recoverable already exists.
And this architectural approach has an advantage the social contract doesn’t: it prevents damage rather than punishing it after the fact. With a human employee, if they make a catastrophic error, the social contract means there are consequences for them — but the damage to the organization is still done. With an AI agent operating inside a well-designed permission structure, the damage never happens in the first place.
The last mile
So the leash will get longer — it already is. Dan Shipper, the CEO of Every, has proposed that the real proxy for AI progress is how long an agent can run independently before a human needs to intervene. Researchers at METR have been measuring this empirically — on standardized benchmarks, the autonomous work horizon for frontier AI agents has been doubling roughly every seven months.
For most knowledge work — writing, coding, analysis, administration — the combination of improving models and maturing infrastructure will steadily extend the leash. We’ll build better permission tiers, better audit trails, better rollback mechanisms. Architecture will substitute for accountability, and it’ll work.
But there’s a category of work where it won’t be enough. When the stakes are irreversible — a critical medical decision, an autonomous weapons system, a trade that moves markets — no amount of permission infrastructure fully solves the problem. Even if the AI is statistically better than the human, there’s still a nonzero probability of error. And for irreversible errors, you can’t undo the damage no matter how good your rollback system is.
This is where the social contract becomes the binding constraint. We’ve seen this play out already with driverless cars. A Swiss Re analysis of 25 million autonomous miles found Waymo vehicles had 88% fewer property damage claims and 92% fewer bodily injury claims than human drivers. But people still feel less safe in them — and I think a key reason is the accountability gap, not the capability gap. When a human driver causes an accident, someone is responsible. When an autonomous vehicle causes one, the absence of a blameable agent feels fundamentally wrong, even if the outcome is better on average.
That response isn’t rational, but it’s deeply human. And I think it’s the real frontier of the leash length problem: not whether AI can do the work, but whether we can accept outcomes from a system that has no skin in the game.
The leash length problem
The leash will get longer in two phases. First, through architecture — permission tiers, memory systems, audit trails, reversibility infrastructure. This is happening now, and it works. My own experience is proof: the right framework turned six months of babysitting into a productive partnership.
The second phase is harder. It requires either inventing accountability mechanisms for AI that satisfy the same psychological need as the social contract — or accepting that for some categories of decisions, AI will be statistically better than humans but we’ll still want a person making the final call, simply because a person can be held responsible.
We solved delegation in human organizations by building infrastructure and relying on a social contract. For AI, the infrastructure is being built. The social contract isn’t — and for most work, it might not need to be. But for the work that matters most, the last mile of the leash isn’t a technical problem. It’s a question of whether we can accept better outcomes from a system that can’t be held responsible for worse ones.
Previously in Ground Truth: The Snapshot Problem explored why smart people can look at AI and see completely different realities. The leash length problem is one reason those snapshots diverge — the people who’ve configured their AI thoughtfully are experiencing a fundamentally different tool than those still running defaults.