
Wrapping the Unpredictable Genius
The model is the one part of an AI product anyone can copy. The advantage is the sum of the rest.

Running your work through AI means building on top of something powerful that won’t always do what you tell it. The fix looks like a power-user trick. It’s the same problem the most ambitious AI products are built around, and it points to where the real, durable advantage lives.
For the better part of this year I had a rule written down that my AI agent kept breaking. It lived in a file Claude must read at the start of every Claude Code session, stated plainly: don’t do this particular thing. It read the rule, agreed with the rule, and every so often did the thing anyway. So I moved the rule out of the documentation and into a piece of code that runs on its own and blocks the action the moment the condition is met. The model doesn’t get a say in that code. It just runs, and the thing it forbids stops happening.
In The Verification Tax I named the cost of running most of your work through AI: the time you spend checking the output. You pay that cost down with upstream engineering instead of more downstream review. This post is about the structure that does the engineering. The rule that kept failing until it moved is the whole idea in miniature. Over the year I built the smallest possible control setup around the model, with just me and my tools.
The control I built is a stack, and only the top layer enforces
Think of it as four layers, from the least control to the most. At the bottom is the model itself (e.g. Claude Opus 4.8, GPT-5.5) . It’s brilliant and it’s unpredictable: ask it the same thing twice and you can get two different answers, and no instruction fully changes that. Above the model runs the harness (e.g. Claude Code, Codex, OpenClaw), the program that operates it and decides what it sees. The harness can steer, but only in broad strokes. Above that sits the documentation (e.g. CLAUDE.md and AGENTS.md): my preferences, the project’s context and rules, the corrections I’ve fed it over months. That’s real influence, but the model still gets a vote. It reads what I wrote, weighs it against everything else, and sometimes goes its own way, which is exactly what mine did. At the top sit hooks. A hook is a piece of code that watches for one specific situation and acts on its own. When the agent reaches for the command I’ve ruled out, the hook blocks it, whether the model agrees or not.
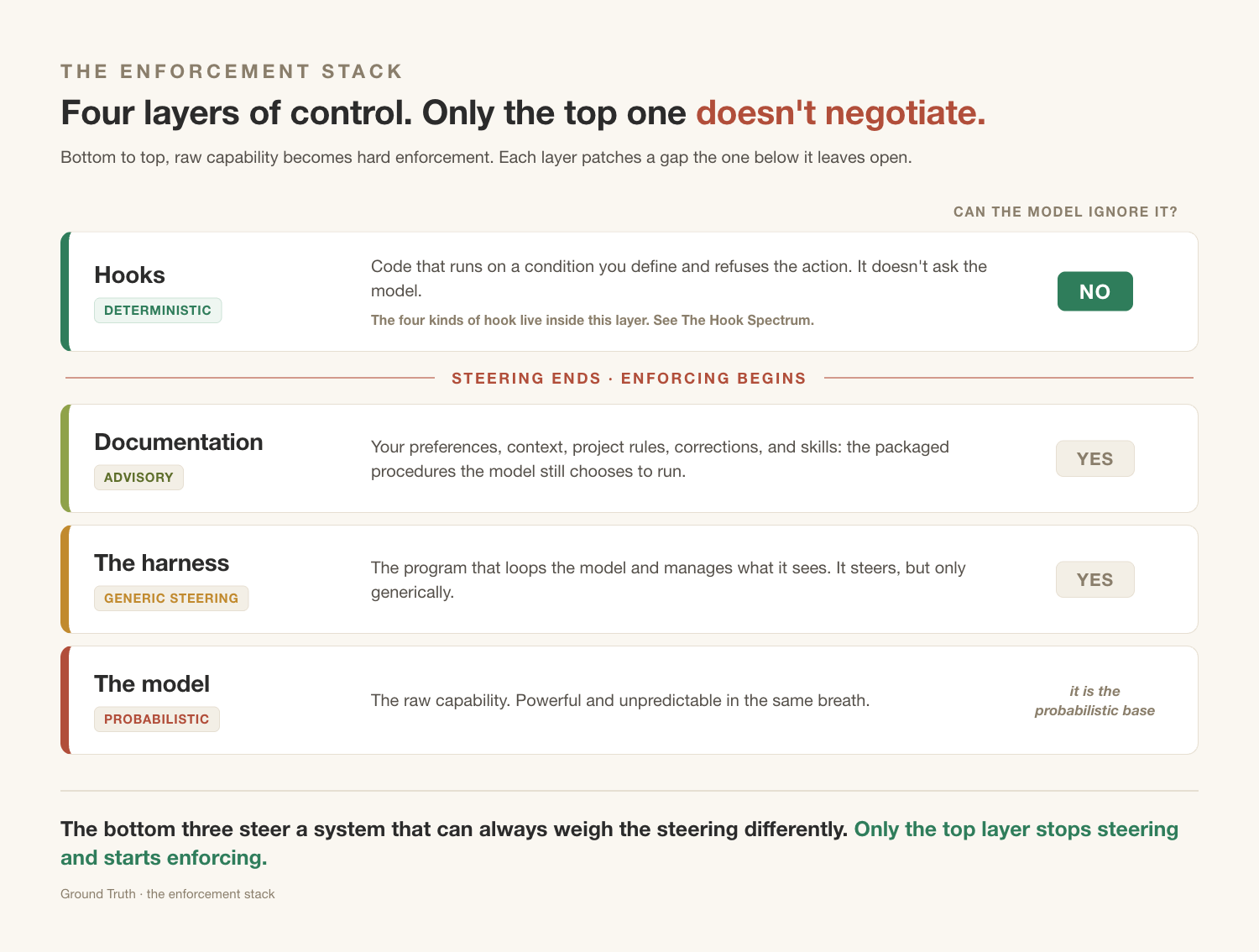
Only the top layer doesn’t negotiate. Anything I can turn into a hook can’t get past it, so there’s less for me to check. The mistakes that used to keep coming back are the ones that simply stopped.
The surface shrinks, but it never closes. Plenty of rules are too judgment-shaped to write as code. “Never run this exact command” is something code can check. “Don’t let the analysis drift into something subtly wrong here” is a judgment, and the only thing that can judge is another model. So those rules send you right back to the unpredictable layer you were trying to get above.1
That’s also why the wrap outlasts every model upgrade. The few systems that can actually prove their output is right all work the same way. They check the answer with code, against a standard a human wrote down ahead of time.2 That works only where you can say exactly what “right” means, and judgment is the thing you can’t. So the wrap is permanent. It covers a gap that never closes, no matter how good the model gets.
What looks like a power-user trick is the whole problem in miniature
Software earned its discipline because code is predictable. You decide what the output should be and test your way to it. AI-native products break that contract: they put a probabilistic engine at the center, one that answers the same prompt differently every time. Hamel Husain put it cleanly: the testing discipline software spent decades building assumes one right answer to test against, which is exactly what you no longer have. That point is well-worn by now. The open question is what replaces it.
A chorus of builders is converging on the same answer: keep the unpredictable engine, but wrap it in deterministic code, code that does the exact same thing every time. Dex Horthy puts it bluntest in his “12-factor agents”: good agents are “comprised of mostly just software.” Anthropic’s guide to building effective agents says the same thing in its own words, telling builders to run the work through “predefined code paths” and “add programmatic checks.”
It’s concrete enough that the tool builders now ship it. In Claude Code you can hold an agent to a condition and choose how it’s checked: back the check with code that passes or fails on its own, which gives you a guarantee, or let a model judge it, which gives you a judgment call.3 My own setup is the smallest version of the same idea: every layer I described is one person’s take on what Horthy means by “mostly software.”
Now scale that up. The architecture doesn’t change, only the cost of a mistake does. On my own, a rule the agent ignores costs me a few minutes, and my hooks catch the ones that matter. Inside a two-hundred-person company running the same agents, no one has private hooks. The rules live in one shared file, so a single ignored instance can show up everywhere that file runs, and the team’s protection is only as good as the loosest rule anyone wrote.
The craft is choosing what to guarantee and what to leave loose
The clearest version of the other half comes from the product side. Every’s guide to agent-native architecture argues that “features aren’t code you write, they’re outcomes you describe, achieved by an agent operating in a loop.” That’s a real shift, and it’s the opposite of my move: lean all the way into the model, let it improvise, and design the product around whatever it produces. But read closely and the guide keeps reaching back toward control anyway. It tells builders to move the hot paths “to code,” and admits some operations “need validation that shouldn’t be left to agent judgment.” Each is one clause, and neither gets developed. That undeveloped corner, the controlled code wrapped around the improvising model, is the half I’ve been living in.
The two camps look like opposites, but they’re describing the same architecture from opposite ends. The product builders lean into the model; the engineers wrap it in control. The real work is in between, and it’s a question of degree: how much of the product do you lock down with code, and where. Lock down too little, and the product improvises somewhere the work needed a guarantee. That’s the failure that ships a confidently wrong answer to a customer. Lock down too much, and you hit the other edge: encode every path in code and you’ve just rebuilt ordinary software, with the model as a slow, expensive way to do what plain code already did.
The whole skill is knowing, point by point through your product, which parts need the model’s judgment and which parts need a guarantee. The OpenAI team calls this “harness engineering.” The part worth naming is doing it in deliberate proportion to the power you’re wrapping.
The wrap is the moat
That proportioning is where the durable advantage hides, because the model itself is the least defensible layer you have. Everyone can rent the same model, and it gets better for everyone at once, on the labs’ schedule, not yours. The wrap is what compounds. The obvious objection is that the wrap is copyable too. But a competitor can read your whole repo and still not have what built it: every judgment you’ve made about what your specific work needs guaranteed and what it can leave loose. Those judgments become the layers the model can’t argue past, and reading the repo won’t hand them over. That accumulated record is the moat.
You can watch this play out in the open. Cursor, the AI coding tool, makes no model of its own. It routes between Claude, GPT, Gemini, and Grok, and treats the model as the rentable commodity it is. Everyone assumed Anthropic’s own Claude Code, with first access to the best model, would end it. It didn’t. Cursor went from about $1B in revenue last November to around $4B by June. Last week SpaceX exercised an option it took in April and agreed to buy the company for $60B, the largest acquisition of a venture-backed startup on record. What Cursor spent years compounding was never a better model. It was the wrap: a codebase index that keeps your whole repository synced and searchable; an autocomplete model trained in-house on which suggestions developers accept or reject, across hundreds of millions of edits a day; and the enterprise plumbing now sitting inside most of the Fortune 500. The model company had the better model and still couldn’t own the editor, the index, or the developer’s muscle memory.
Few have built what Cursor has. Most people running AI through their work haven’t built a single layer of this wrap, and don’t yet know the layer exists. At company scale, it’s the build question that decides which AI-native products hold up under real use and which ones are just a brilliant demo over a model anyone can rent.
If the model you build on became free tomorrow, what would you have left?
Previously in Ground Truth: The Judgment Layer (when the feedback loop can’t close, and what survives when it doesn’t) · The Verification Tax (the cost of checking AI output, and how upstream engineering pays it down).
The practitioner’s field guide for building this layer, matching failures to hook types and working out what you can and can’t measure at each tier, is the piece I published on X.
A recent line of work delivers real correctness guarantees for AI agents, and every one earns the guarantee the same way: by checking the output with code, against a formal spec a human wrote. SEVerA can guarantee an agent’s output meets a formal contract, but the contract has to be written out in formal logic up front, and it only works in domains you can check that way. VeriGuard adds verified safety to LLM agents, but the guarantee still depends on the user validating it by hand: an LLM does the translation from intent into formal rules, and that step is itself unpredictable. Every real guarantee bottoms out at a fixed check against a human-written spec. Systems marketed as “self-improving agents” do something different: they score what happened and feed it forward so the agent improves over time, which is not the same as proving any single output is right.
Two Claude Code features map onto the layers directly. Skills are packaged, opinionated procedures the agent can call; they sit in the documentation layer, more structured than a loose rule but still advisory, since the model chooses whether to run one and can wander off mid-way. /goal sits at the enforcement line: it keeps the agent working until a stated condition is met, with a small fast model judging after each turn whether the condition holds, which can misread the way any model can. /goal is a wrapper around a Stop hook, and a Stop hook you write yourself can instead run a script that passes or fails on its own. The docs draw the line plainly: a script for a deterministic check, a model for a judged one.